总体介绍
Fluxon 提供的是建立在 KV 底座之上的消息队列能力。它不是一套独立于 KV 的新服务,而是复用同一套服务平面、同一套本机共享内存池,以及同一个 Python client 接入内核,在这个基础上提供 producer / consumer 语义。
如果先按层级架构看,MQ 相关对象可以分成三层:
- 服务平面:
etcd、greptime、fluxonkv master。这一层负责元数据、成员关系、路由、租约以及标准监控链路。 - 本机数据面常驻实例:
owner。这一层在本机长期驻留,提供共享内存池和本机数据面资源,角色上更接近一个本机 daemon。 - 业务进程接入层:
FluxonKvClientConfig、new_store(...)返回的KvClient(store)、以及继续绑定出来的producer/consumer。这一层负责让业务进程以 external client 身份附着到同机owner,再继续使用 MQ API 收发消息。
因此,使用时可以先按下面这条生命周期依赖关系来理解:
etcd + greptime + fluxonkv master
|
v
kvclient owner
|
v
+--------------------------------------------------------------+
| kvclient external |
| FluxonKvClientConfig -> new_store(...) -> KvClient(store) |
+--------------------------------------------------------------+
|
+-> new_or_bind_with_unique_key(...)
|
+-> producer
+-> consumerowner、external client、shared memory 这些前置概念见 架构和概念;new_store(...) -> KvClient 的配置和基础语义见 KV 和 RPC 接口。
MQ 用户侧有一个固定角色约束:producer / consumer 必须以 external_client 模式运行,也就是 zero-contribution 模式。原因很直接:producer / consumer 会动态加入和离开,这些业务侧进程不应改变集群容量;容量提供者应当始终是常驻的 owner。
服务平面
在进入 producer / consumer 代码之前,需要先把 MQ 依赖的服务平面拉起来。共性的角色关系、启动顺序和 runtime 边界,统一见 用户 - 2 - 服务平面。
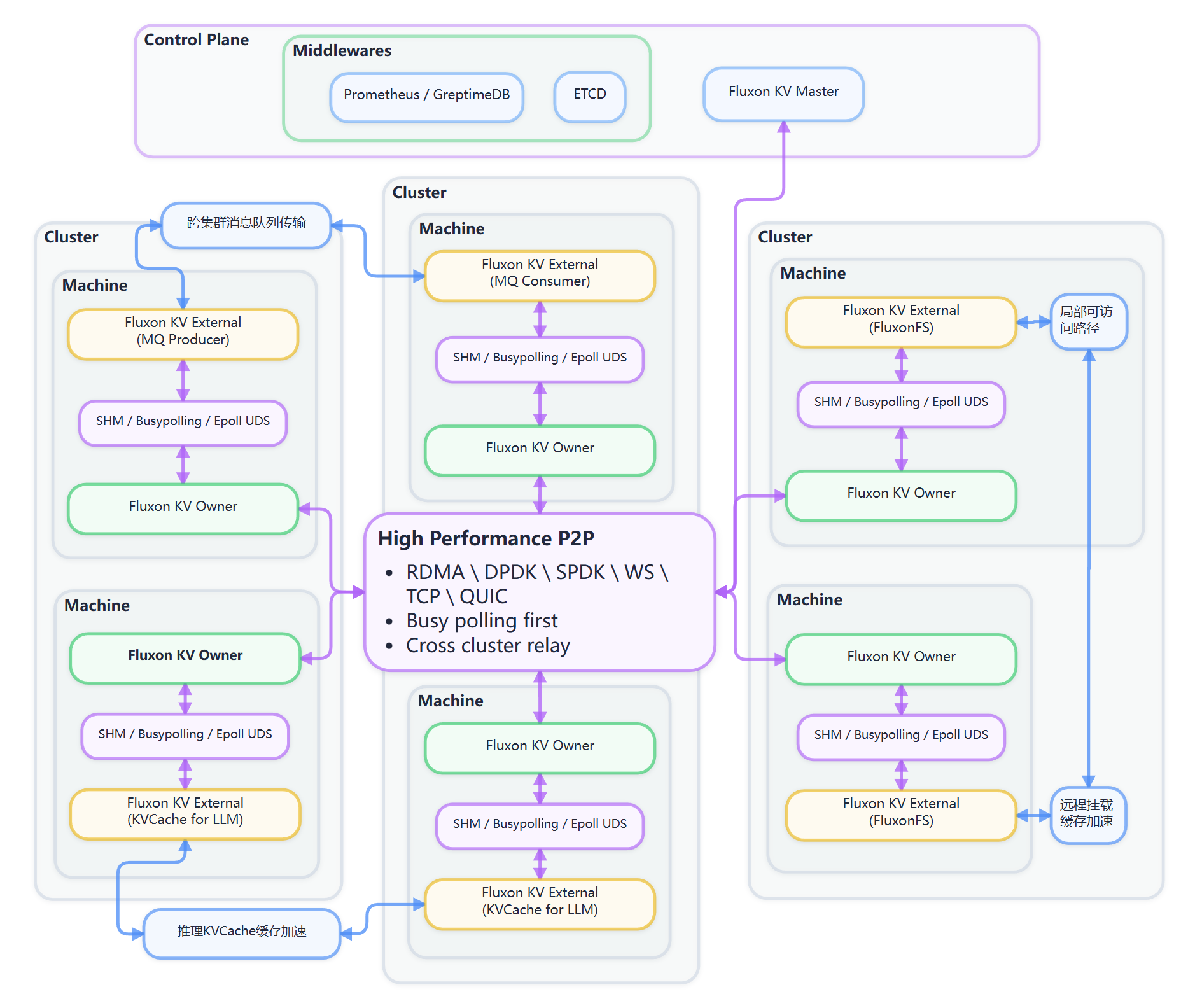
MQ 直接复用 KV 服务平面,没有自己独立的一套底座。直接接触的服务平面对象主要有:
greptime:用于标准监控链路。安装与启动见 用户 - 2 - 服务平面etcd:MQ / KV 服务平面元数据存储。安装与启动见 用户 - 2 - 服务平面start_kv_master_process(...):启动fluxonkv masterstart_owner_kvclient_process(...):启动owner
MQ 用户进程的最小前置链路如下:
- 先起
greptime - 再起
etcd - 再起
fluxonkv master - 再起
owner - 最后再运行 producer / consumer
最小可运行示例脚本如下。MQ 复用的就是这条 KV 角色启动链路;这个脚本只启动 Fluxon 自己的角色,etcd / greptime 仍按服务平面文档单独启动:
- 当前
python3所在环境已经安装统一的fluxon_ai-*.whl;安装方式见 用户 - 0 - 安装
对应示例脚本:examples/start_master_owner.py
这个脚本支持两种启动方式:
- 默认方式:启动
master + owner --without-master:只启动owner,接入已经存在的 KV 集群master
#!/usr/bin/env python3
import argparse
from pathlib import Path
from fluxon_py.runtime import (
start_kv_master_process,
start_owner_kvclient_process,
wait_subproc_or_ctrlc,
)
from fluxon_py.runtime.process_runner import ManagedSubprocess
ETCD_ENDPOINT = "127.0.0.1:2379"
GREPTIME_HTTP_PORT = 34030
GREPTIME_BASE_URL = f"http://127.0.0.1:{GREPTIME_HTTP_PORT}"
CLUSTER_NAME = "demo-kv-cluster"
SHARE_MEM_PATH = Path("/dev/shm/fluxon_kv_demo").resolve()
WORKDIR = Path("/tmp/fluxon_kv_demo/runtime").resolve()
MASTER_PORT = 31000
MASTER_INSTANCE_KEY = "demo_kv_master"
OWNER_INSTANCE_KEY = "demo_kv_owner"
OWNER_DRAM_BYTES = 1073741824
def main() -> None:
args = parse_args()
log_dir = (WORKDIR / "log").resolve()
if args.with_master:
master_log_dir = (WORKDIR / "master_logs").resolve()
master_log_dir.mkdir(parents=True, exist_ok=True)
master_stdout_log = log_dir / "master.log"
master_proc = start_kv_master_process(
config=build_master_config(log_dir=master_log_dir),
log_path=master_stdout_log,
)
else:
master_stdout_log = None
master_proc = None
owner_stdout_log = log_dir / "owner.log"
owner_proc = start_owner_kvclient_process(
config=build_owner_config(),
log_path=owner_stdout_log,
)
children = []
if master_proc is not None:
children.append(
ManagedSubprocess(
label="master",
proc=master_proc,
)
)
children.append(
ManagedSubprocess(
label="owner",
proc=owner_proc,
)
)
print(f"[fluxon_kv] share_mem_path: {SHARE_MEM_PATH}")
print(f"[fluxon_kv] etcd endpoint: {ETCD_ENDPOINT}")
print(f"[fluxon_kv] greptime base url: {GREPTIME_BASE_URL}")
print(f"[fluxon_kv] start master in this script: {args.with_master}")
if master_stdout_log is not None:
print(f"[fluxon_kv] master stdout log: {master_stdout_log}")
else:
print("[fluxon_kv] master stdout log: disabled by --without-master")
print(f"[fluxon_kv] owner stdout log: {owner_stdout_log}")
stack_label = "master and owner" if args.with_master else "owner"
print(f"[fluxon_kv] waiting for Ctrl-C to stop {stack_label}")
wait_subproc_or_ctrlc(
children,
on_ctrlc=lambda: print(f"[fluxon_kv] caught Ctrl-C, stopping {stack_label}"),
)
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(description="Start KV demo owner, optionally with a local master")
group = parser.add_mutually_exclusive_group()
group.add_argument(
"--with-master",
dest="with_master",
action="store_true",
help="Start a local kv master in this script (default)",
)
group.add_argument(
"--without-master",
dest="with_master",
action="store_false",
help="Do not start a local kv master; only start owner and attach to an existing cluster master",
)
parser.set_defaults(with_master=True)
return parser.parse_args()
def build_master_config(*, log_dir: Path) -> dict:
return {
"instance_key": MASTER_INSTANCE_KEY,
"cluster_name": CLUSTER_NAME,
"port": MASTER_PORT,
"etcd_endpoints": [ETCD_ENDPOINT],
"log_dir": str(log_dir),
"monitoring": {
"prometheus_base_url": f"{GREPTIME_BASE_URL}/v1/prometheus",
"prom_remote_write_url": [f"{GREPTIME_BASE_URL}/v1/prometheus/write"],
"otlp_log_api": {
"otlp_endpoint": f"{GREPTIME_BASE_URL}/v1/otlp/v1/logs",
},
},
}
def build_owner_config() -> dict:
return {
"instance_key": OWNER_INSTANCE_KEY,
"contribute_to_cluster_pool_size": {
"dram": OWNER_DRAM_BYTES,
"vram": {},
},
"fluxonkv_spec": {
"etcd_addresses": [ETCD_ENDPOINT],
"cluster_name": CLUSTER_NAME,
"share_mem_path": str(SHARE_MEM_PATH),
"sub_cluster": "default",
"large_file_paths": [str((WORKDIR / "large" / "owner").resolve())],
},
}
if __name__ == "__main__":
main()启动命令:
python3 examples/start_master_owner.py
python3 examples/start_master_owner.py --without-master默认命令会启动本机 master + owner。--without-master 只启动本机 owner,要求同一个 cluster_name 对应的 master 已经在别处运行。
owner 把共享内存池和 shared.json 准备好之后,再运行下面的 MQ 最小示例。默认模式下,这个服务平面脚本会把子进程终端输出写到 WORKDIR/log/master.log 和 WORKDIR/log/owner.log,终端只保留摘要信息;--without-master 模式下只会生成 WORKDIR/log/owner.log。
cluster、owner_client、external_client、shared memory 这些前置概念见 架构和概念;new_store(...) -> KvClient 的配置和基础语义见 KV 和 RPC 接口。
对象关系
new_store(...) 和 MQ handle 的关系如下:
FluxonKvClientConfig
|
v
new_store(cfg) -> KvClient (store)
|
+-- new_or_bind_with_unique_key(
| store,
| chan_config,
| unique_id,
| chan_type,
| chan_role,
| )
|
+-- producer handle
| put_data(...)
| close()
|
+-- consumer handle
| get_data(...)
| close()
|
v
store.close()关键关系如下:
new_store(...)构造的是KvClient;本页里的store只是示例变量名KvClient的基础语义、配置字段、external_client约束都在 KV 和 RPC 接口 里定义new_or_bind_with_unique_key(...)不是独立入口,它必须运行在store之上- 退出顺序固定是:先
producer.close()/consumer.close(),再store.close()
关闭生命周期
用户和测试代码只需要调用两层公共接口,顺序固定:
producer.close().unwrap("close MQ producer failed")
# 如果当前角色是 consumer:
# consumer.close().unwrap("close MQ consumer failed")
store.close().unwrap("close KV store failed")同一个 store 上有多个 MQ handle 时,必须先调用所有 handle 的 close() 并消费结果,再调用 store.close()。两层 close() 都返回 Result[OkNone, ApiError];关闭错误必须记录或向上传播,不能静默丢弃。
MQ endpoint 的关闭结果按资源类型区分:
| 关闭动作 | 失败语义 |
|---|---|
| 停止数据路径、MQ runtime、后台任务和本地 handle | 必须完成;失败时 close() 返回 ApiError。 |
| 删除绑定了 lease 的 role、ready、membership、weight key | 只做一次尽力删除;失败时记录 WARN、继续释放 keepalive handle,并由 backend lease TTL 回收。 |
| 创建、绑定、发布、ready claim、消息确认和 offset 更新等运行中 etcd 操作 | 保持强契约;失败时当前操作返回错误。 |
因此,leased key 的删除告警表示显式回收延后到 TTL,不表示本地 endpoint 仍未关闭。调用方仍应消费 close() 的 Result,但不需要读取私有对象或自行重试分布式 key 删除。
sequenceDiagram participant App as 用户 / 测试代码 participant Endpoint as producer / consumer participant Internal as endpoint 内部 MQ 资源 participant Store as KvClient App->>Endpoint: close() Endpoint->>Internal: 停止数据路径并回收内部资源 Internal-->>Endpoint: 本地关闭完成;leased key 已删除或交给 TTL Endpoint-->>App: Result[OkNone, ApiError] App->>Store: close() Store-->>App: Result[OkNone, ApiError]
职责边界如下:
| 责任方 | 负责内容 |
|---|---|
| 用户 / 测试代码 | 调用公共 producer.close() / consumer.close(),检查返回的 Result,然后调用 store.close()。 |
| MQ endpoint | 在 close() 内部停止收发路径,关闭所属子通道和 MQ runtime,并结束由该 endpoint 持有的 keepalive 与后台任务;leased key 删除失败时记录 WARN 并启动 TTL 兜底。Fluxon KV lease keepalive 始终留在 Rust 生命周期内。 |
KvClient | 在 MQ endpoint 全部关闭后回收 KV client 资源。 |
MQ endpoint 的内部生命周期对调用方不可见。用户代码、示例和测试都不应创建 lease manager 对象或 Python keepalive 回调,也不应访问私有字段、原始 shutdown controller 或 MQ framework。等待、强制退出或静默丢弃 close() 的 Result 都不能代替上述两步。
MQ接口最小示例
跑通一对 producer / consumer 的最小对象如下:
examples/start_mpmc_demo.py
它只保留一个命令参数:
--role producer--role consumer
先把服务平面拉起来,然后分别运行:
python3 examples/start_mpmc_demo.py --role producer
python3 examples/start_mpmc_demo.py --role consumer这个最小示例里,producer 每成功发送一条消息,就把本进程内的 seq 加 1;如果你重启 producer 进程,计数会从 1 重新开始,而不是跨进程持久延续。
对应的真实脚本内容如下:
#!/usr/bin/env python3
import argparse
import threading
from pathlib import Path
from fluxon_py.api_ext_chan import ( # type: ignore
ChanRole,
ChanType,
new_or_bind_with_unique_key,
)
from fluxon_py.api_error import ChannelClosedError, ProducerClosedError # type: ignore
from fluxon_py.config import FluxonKvClientConfig # type: ignore
from fluxon_py.kvclient import new_store # type: ignore
from fluxon_py.logging import init_logger # type: ignore
from fluxon_py.runtime import register_ctrlc_callback
# These constants are the only user-facing knobs in the minimal example.
CLUSTER_NAME = "demo-kv-cluster"
SHARE_MEM_PATH = "/dev/shm/fluxon_kv_demo"
CHANNEL_KEY = "demo_mq_channel_doc"
CHANNEL_CAPACITY = 128
CHANNEL_TTL_SECONDS = 300
PRODUCER_INTERVAL_SECONDS = 1.0
CONSUMER_BATCH_SIZE = 1
def _must_ok(res, msg: str):
if not res.is_ok():
raise SystemExit(f"{msg}: {res.unwrap_error()}")
return res.unwrap()
def _best_effort_close_result(obj, logger, role: str) -> None:
try:
close_res = obj.close()
except Exception as e: # noqa: BLE001
logger.warning(f"[{role}] close raised (ignored): {e}")
return
if close_res.is_ok():
_ = close_res.unwrap()
else:
logger.warning(f"[{role}] close error (ignored): {close_res.unwrap_error()}")
def _build_store_config(*, role: str) -> FluxonKvClientConfig:
# MQ first attaches to the local owner via one external KvClient,
# then binds a producer or consumer handle on top of that store.
return FluxonKvClientConfig(
{
"instance_key": f"demo_mq_{role}",
"fluxonkv_spec": {
"cluster_name": CLUSTER_NAME,
"share_mem_path": SHARE_MEM_PATH,
},
}
)
def _run_producer(store, logger, shutdown_requested: threading.Event) -> None:
interrupted = False
closed = False
producer = None
restore_signal_listener = lambda: None
seq = 1
try:
# Producer and consumer must bind the same channel key so they land on
# the same channel id.
producer = _must_ok(
new_or_bind_with_unique_key(
store,
{"capacity": CHANNEL_CAPACITY, "ttl_seconds": CHANNEL_TTL_SECONDS},
unique_id=CHANNEL_KEY,
chan_type=ChanType.MPMC,
chan_role=ChanRole.PRODUCER,
),
"bind producer failed",
)
def _on_ctrlc(reason: str) -> None:
nonlocal interrupted, closed
# The signal callback only requests shutdown and closes the handle once.
# The main loop still exits through its normal close-observation path.
interrupted = True
shutdown_requested.set()
if closed:
return
closed = True
logger.info(f"[producer] caught {reason}, calling close...")
_best_effort_close_result(producer, logger, "producer")
restore_signal_listener = register_ctrlc_callback(
_on_ctrlc,
thread_name="mpmc-demo-producer-signal",
)
logger.info(f"[producer] ready: channel_key={CHANNEL_KEY}")
while not shutdown_requested.is_set():
payload_text = f"hello mq #{seq}"
payload = payload_text.encode("utf-8")
put_res = producer.put_data(
{
"seq": seq,
"payload": payload,
}
)
if put_res.is_ok():
_ = put_res.unwrap()
logger.info(f"[producer] sent: seq={seq} payload={payload_text}")
seq += 1
else:
err = put_res.unwrap_error()
# ProducerClosedError is the expected signal that close() already
# propagated into the handle, not an unexpected data-path failure.
if isinstance(err, ProducerClosedError):
logger.info("[producer] close observed, exit loop")
break
raise SystemExit(f"put_data failed: {err}")
if shutdown_requested.wait(PRODUCER_INTERVAL_SECONDS):
break
finally:
restore_signal_listener()
# Handle lifetime must end before store lifetime.
if producer is not None and not closed:
_best_effort_close_result(producer, logger, "producer")
if interrupted:
raise SystemExit(130)
def _run_consumer(store, logger, shutdown_requested: threading.Event) -> None:
interrupted = False
closed = False
consumer = None
restore_signal_listener = lambda: None
try:
# Consumer binds the same channel key as producer and only changes role.
consumer = _must_ok(
new_or_bind_with_unique_key(
store,
{"capacity": CHANNEL_CAPACITY, "ttl_seconds": CHANNEL_TTL_SECONDS},
unique_id=CHANNEL_KEY,
chan_type=ChanType.MPMC,
chan_role=ChanRole.CONSUMER,
),
"bind consumer failed",
)
def _on_ctrlc(reason: str) -> None:
nonlocal interrupted, closed
# Keep the callback minimal: request shutdown, close the MQ handle once,
# and let the main loop observe ChannelClosedError.
interrupted = True
shutdown_requested.set()
if closed:
return
closed = True
logger.info(f"[consumer] caught {reason}, calling close...")
_best_effort_close_result(consumer, logger, "consumer")
restore_signal_listener = register_ctrlc_callback(
_on_ctrlc,
thread_name="mpmc-demo-consumer-signal",
)
logger.info(f"[consumer] ready: channel_key={CHANNEL_KEY}")
while not shutdown_requested.is_set():
get_res = consumer.get_data(batch_size=CONSUMER_BATCH_SIZE)
if not get_res.is_ok():
err = get_res.unwrap_error()
# ChannelClosedError is the normal close path after Ctrl-C/SIGTERM.
if isinstance(err, ChannelClosedError):
logger.info("[consumer] close observed, exit loop")
break
raise SystemExit(f"get_data failed: {err}")
for item in get_res.unwrap() or []:
payload = item.get("payload", b"") if isinstance(item, dict) else item
seq = item.get("seq") if isinstance(item, dict) else None
if isinstance(payload, (bytes, bytearray, memoryview)):
logger.info(
f"[consumer] got: seq={seq} payload={bytes(payload).decode('utf-8', 'ignore')}"
)
else:
logger.info(f"[consumer] got: seq={seq} payload={payload}")
if shutdown_requested.wait(0.2):
break
finally:
restore_signal_listener()
# Always close the consumer before main() closes the backing store.
if consumer is not None and not closed:
_best_effort_close_result(consumer, logger, "consumer")
if interrupted:
raise SystemExit(130)
def main() -> None:
parser = argparse.ArgumentParser(description="Start MQ minimal demo")
parser.add_argument("--role", choices=["producer", "consumer"], required=True)
args = parser.parse_args()
# The minimal example keeps share_mem_path explicit and local.
# init_logger() reads FLUXON_LOG and sets the user-process console log level.
logger = init_logger(f"mpmc_demo_{args.role}")
shutdown_requested = threading.Event()
store = None
try:
store = _must_ok(new_store(_build_store_config(role=args.role)), "new_store failed")
if args.role == "producer":
_run_producer(store, logger, shutdown_requested)
else:
_run_consumer(store, logger, shutdown_requested)
finally:
store_to_close = store
store = None
# Store is closed last because MQ handles are already closed inside _run_*.
if store_to_close is not None:
_best_effort_close_result(store_to_close, logger, "store")
logger.info(f"[{args.role}] exit")
if __name__ == "__main__":
main()这个最小示例对应的前置条件只有一条:
- 先把
greptime + etcd + master + owner这套服务平面拉起来
代码块里的注释已经把这份最小示例最容易混淆的局部因果直接写在对应位置,包括:
- 每个全局常量控制什么
new_store(...)和 MQ handle 的先后关系Ctrl-C回调为什么只做“设置退出标志位 + 调一次 close()”ProducerClosedError/ChannelClosedError为什么是正常关闭路径- 为什么一定是先关 handle,再关
store
常见启动方式:
FLUXON_LOG=INFO python3 examples/start_mpmc_demo.py --role producer
FLUXON_LOG=DEBUG python3 examples/start_mpmc_demo.py --role consumer常用接口
new_or_bind_with_unique_key(api, chan_config, unique_id, chan_type, chan_role):存在则 bind,不存在则创建producer.put_data(value: FlatDict) -> Result[bool, ApiError]:写一条消息consumer.get_data(batch_size: int = 1, try_time: Optional[int] = None, prefetch_num: int = 0) -> Result[List[Any], ApiError]:按批拉消息producer.get_chan_id()/consumer.get_chan_id():查看当前 handle 绑定的chan_idproducer.get_producer_id()/consumer.get_consumer_id():查看当前 member idclose() -> Result[OkNone, ApiError]:关闭当前 MQ handle
参数约束如下:
chan_type当前最常用的是ChanType.MPMC,也支持ChanType.MPSCchan_role只能是ChanRole.PRODUCER或ChanRole.CONSUMERtry_time是秒级等待上限;如果需要阻塞拉取窗口控制,再看prefetch_num
关键接口常见错误处理
new_or_bind_with_unique_key(...)失败:直接把unwrap_error()打出来,先检查cluster_name、share_mem_path、unique_id、chan_role是否和对端一致producer.put_data(...)返回ProducerClosedError:按正常关闭路径处理,直接退出主循环consumer.get_data(...)返回ChannelClosedError:按正常关闭路径处理,直接退出主循环
日志路径
日志路径如下:
- MQ Python 部分:由
init_logger(...)初始化,直接输出到当前终端,不默认落盘,门限由FLUXON_LOG控制 - MQ Rust / KV 后台部分:和 KV 一起走服务平面的后台日志链路;
master本地日志目录由master_cfg["log_dir"]指定 share_mem_path:KV 共享 bundle 根目录,只承载mmap.file、shared.json和 peer metadata;后端日志、profile、cache 从 owner 的large_file_paths派生
如果服务平面的 master.monitoring.otlp_log_api 已经配置,MQ Rust / KV 后台部分的日志还会继续采集到 Greptime 的 fluxon_logs 表。
网页监控
网页监控页面里直接可用的对象有两个:
Channels表:看 channel 级汇总Members表:看单个 producer / consumer 明细
查看 Channel 汇总
Channels 表适合先看每个 channel 的整体状态,尤其是积压量和各个 producer 的写入进度。
重点字段:
producer_offsets 是 channel 下每个 producer 的 offset 明细,格式是:
producer_idx: produce_offset/consume_offset例如:
producer_1: 101/88, producer_2: 57/57这里的两个 offset 都表示“下一条 offset”:
produce_offset:这个 producer 下一条将要写入的 offsetconsume_offset:consumer 下一条将要提交的 offset
所以单个 producer 的当前未消费量就是:
max(produce_offset - consume_offset, 0)current_inflight 就是这个 channel 下所有 producer 上面这项的求和。
常见查看方式:
current_inflight持续升高,同时某一个 producer 在producer_offsets里差值越来越大- 说明这个 producer 的消息在持续堆积
current_inflight接近0- 说明当前 channel 基本被消费干净
producer_offsets里多个 producer 都有明显差值- 说明积压不是单个 producer 偏斜,而是整个 channel 消费跟不上
查看 Producer / Consumer 明细
Members 表适合继续下钻到单个 producer / consumer。
重点字段:
channel_unique_keys:显示这个 member 所属 channel 的unique_id绑定 keyproduce_offset/consume_offset:查看单个成员当前的写入位置和消费提交位置chan_id、owner_id、external_client_id:继续定位这个成员属于哪个 channel、owner 和 external client
从 Python 侧用 new_or_bind_with_unique_key(...) 接入 MQ 时,定位方式如下:
- 先在
Members表搜channel_unique_keys - 找到对应 row 之后,再看它的
chan_id、owner_id、external_client_id、offset 和消费延迟字段
这里要注意一个边界:
- 页面里显示的
channel_unique_keys仍然是 channel 级 key - 当前监控页面没有单独暴露“某个 producer / consumer 实例自己的 unique member id”,因为现有 snapshot 权威数据里没有这个对象
筛选与排序
网页监控里的 Channels / Members 两张表都支持和 KV 页面同一套字段排序:
- 可以在表头上方的
Sort #1到Sort #4里选字段排序 producer_offsets和current_inflight都支持这套排序channel_unique_keys也支持过滤和排序,适合直接按 Python 侧传入的unique_id查 channelproducer_offsets适合做文本过滤,快速定位某个 producercurrent_inflight适合做排序,快速找到当前积压最大的 channel
延迟排查
MQ 每 30s 在日志中打印一次消费延迟统计。如果遇到消费慢的问题,按以下关键词搜索日志:
| 日志关键词 | 观测层 | 说明 |
|---|---|---|
py-get latency | Python 调用侧 | 用户调用 get_data() 的总耗时 |
get_one breakdown | PyO3 层 | 跨语言桥接等待时间拆分 |
MpscConsumer prefetch | Rust MQ 层 | 预取队列和单条任务耗时 |
快速定位:
py-get总耗时高 → 先看 PyO3 层的avg_wait_rx_ms是否大- Rust 层
avg_get_handle_ms高 → 预取队列为空,可能是生产侧无数据或窗口过小 - Rust 层
avg_handle_await_ms高 → 单条任务本身慢,例如kv_get或 etcd 提交慢